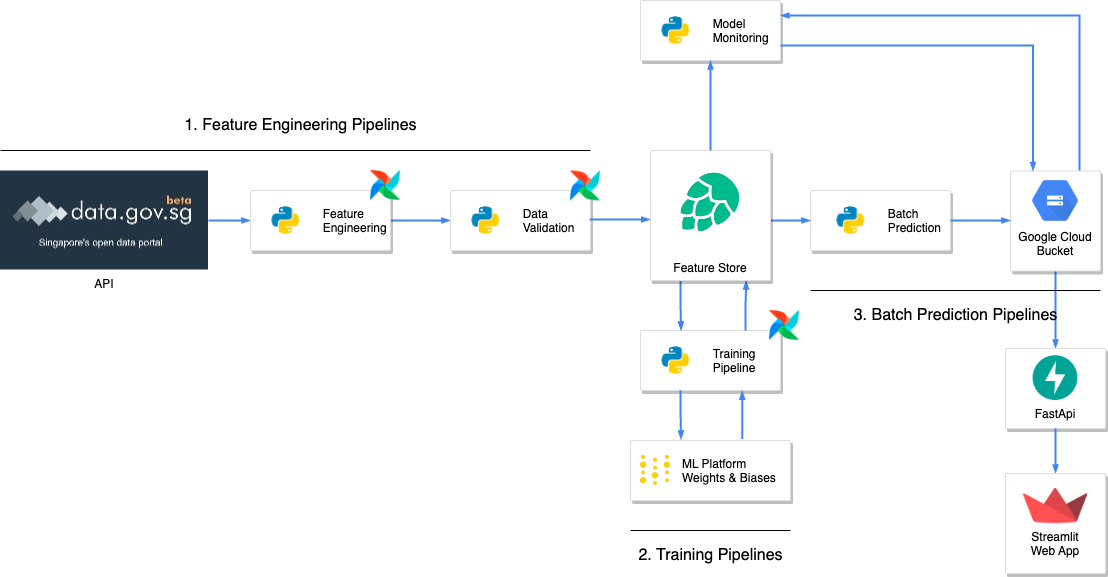
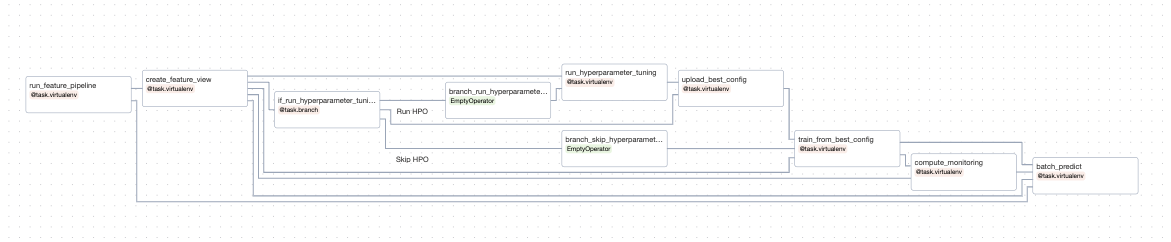
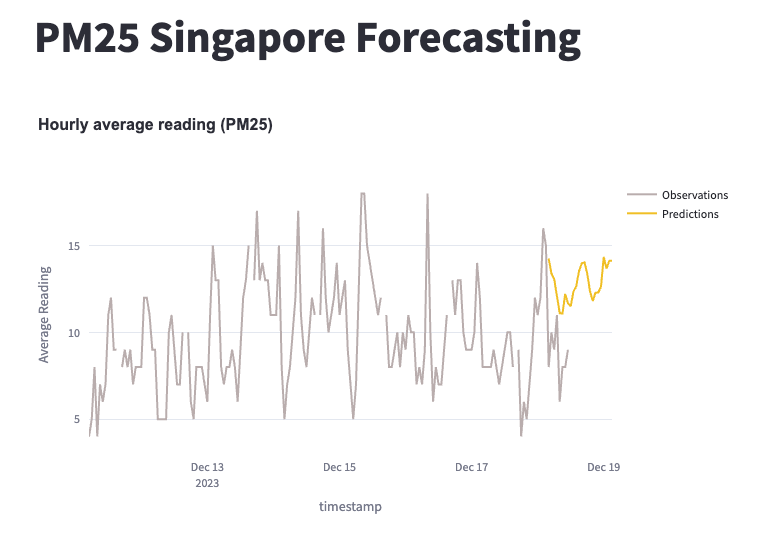
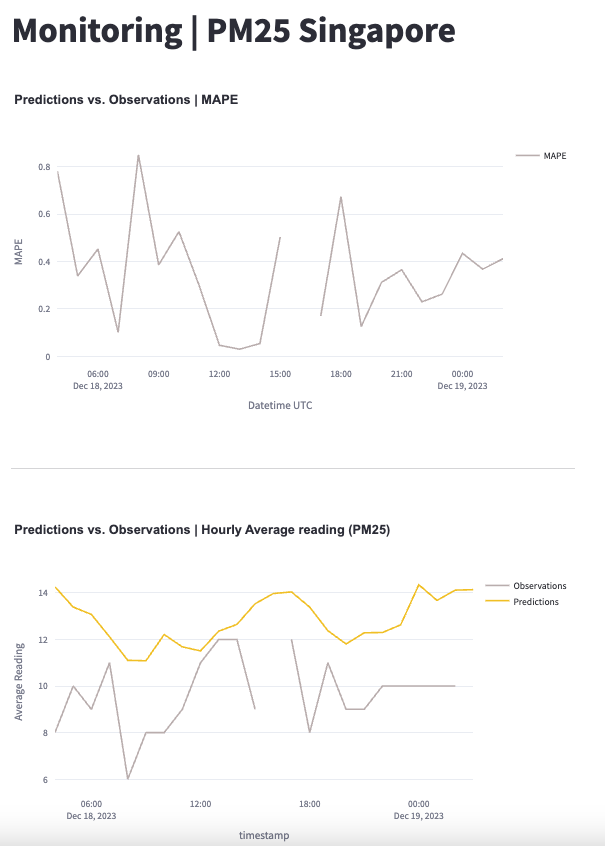
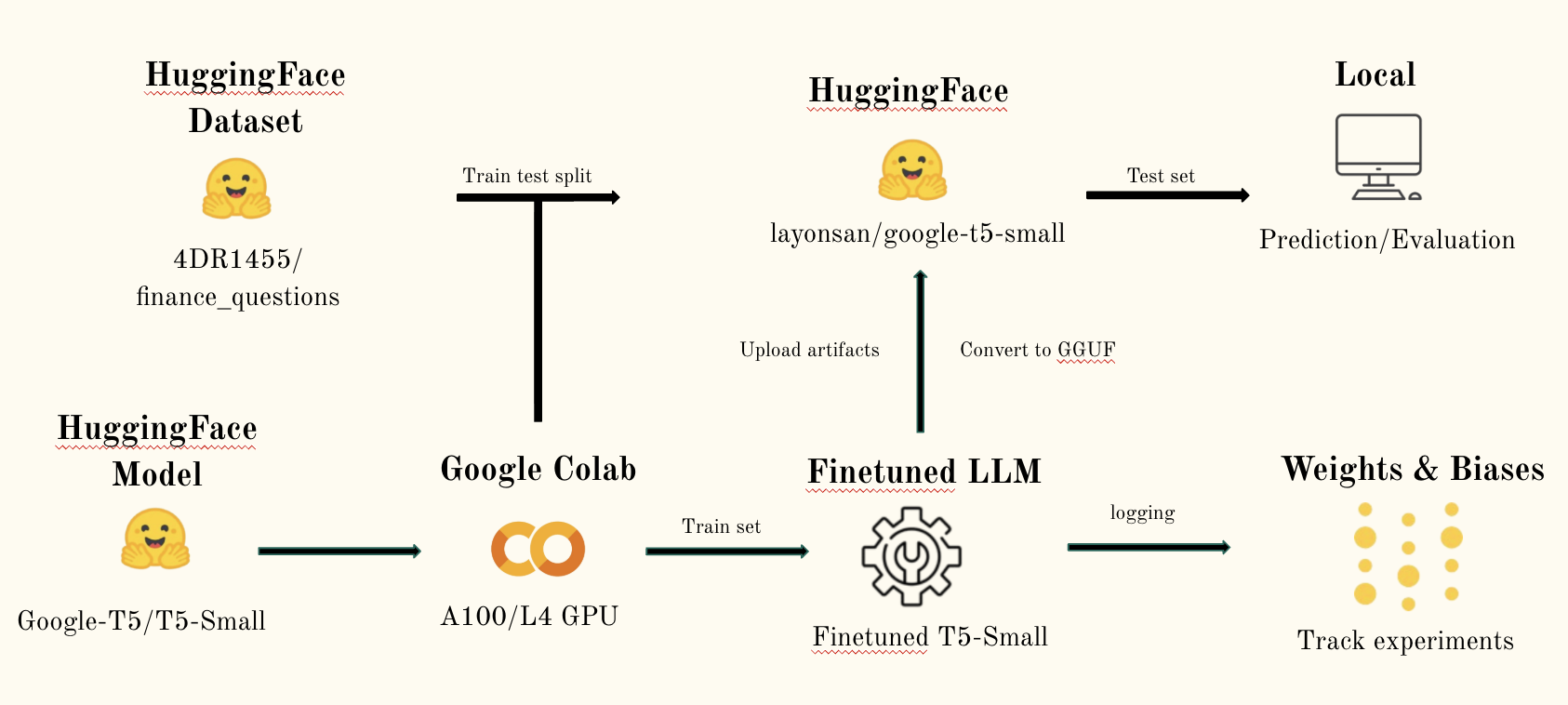
Overall Methodology
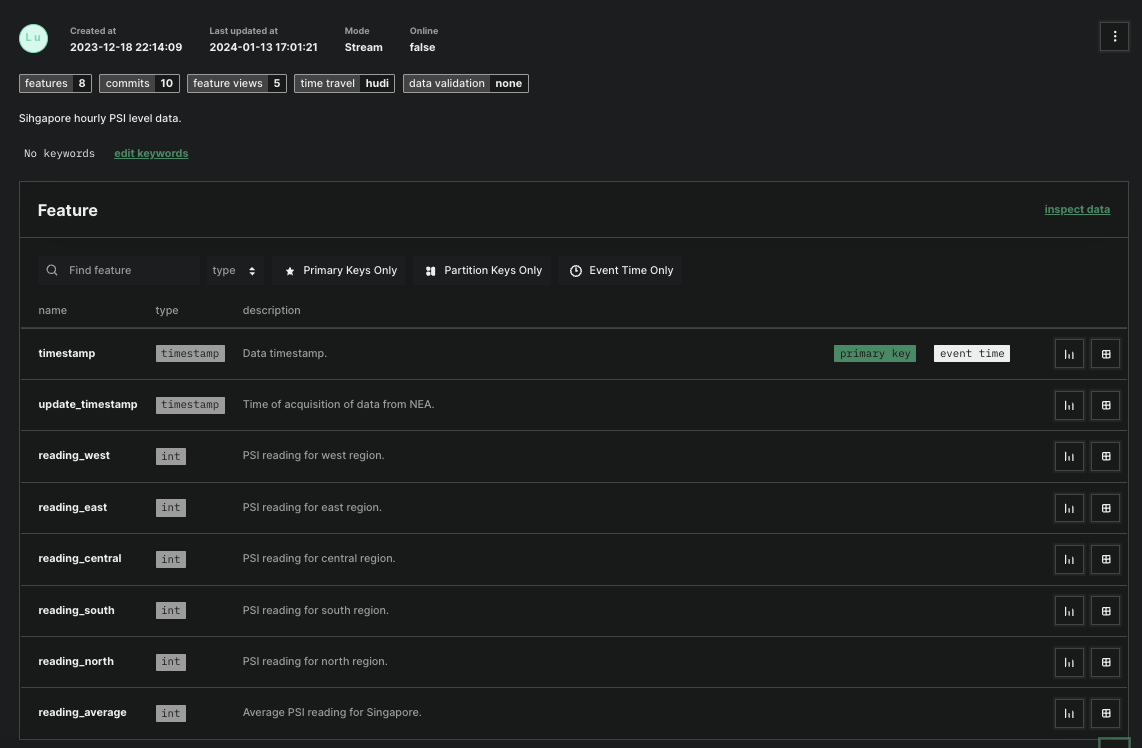
Data
The dataset utilized is a comprehensive financial instruction dataset sourced from Huggingface, specifically the 4DR1455/finance_questions collection. This dataset comprises 53,837 records, providing a robust foundation for the fine-tuning process of Large Language Models (LLMs) using federated learning techniques. Given its substantial size and focus on financial instructions, this dataset offers a rich variety of financial queries and responses, making it particularly suitable for training LLMs to understand and generate finance-related content.
Frameworks for Federated LLMs
There are several emerging frameworks designed to support federated fine-tuning of large language models:
- OpenFedLLM: Provides a concise framework for federated instruction tuning and federated value alignment, with support for multiple domains (e.g., finance, education) and techniques like LoRA for parameter-efficient fine-tuning.
- FederatedScope-LLM (FS-LLM): An extension of the FederatedScope platform with modules for benchmarks, algorithms, and training workflows, making it easier to evaluate and experiment with federated LLMs.
Both are exciting contributions, but they’re still very new and face challenges like limited community support, unclear backwards compatibility, and adoption barriers in real-world applications.
Why I Used Flower
I chose to build on Flower, an open-source federated learning framework that has gained stronger traction and community adoption.
- Proven foundation: Flower focuses on federated learning and privacy-enhancing technologies, with practical use cases demonstrated in both academia and industry
- Community & support: Unlike newer frameworks, Flower already has an active developer community, more robust documentation, and backing from venture funding (Felicis Ventures), giving it momentum for long-term sustainability.
- Origins: Flower started as a research project at the University of Cambridge and later evolved into Flower Labs, an AI startup.
- Practical relevance: Within the federated learning landscape, Flower is increasingly used in real-world implementations, making it a reliable choice for experimentation with federated fine-tuning of LLMs.
Federated Learning Strategies Used
I experimented with five different federated learning strategies to fine-tune large language models (LLMs). Each strategy tackles the challenge of training models across distributed, non-shared datasets in slightly different ways:
-
FedAvg (Federated Averaging) The classic baseline in federated learning. Each client trains locally, and then the server averages the updates, weighted by data size. It’s simple and communication-efficient, but struggles when client data is very different (non-IID).
-
FedProx An improvement over FedAvg. It adds a “proximal term” during training to keep local updates closer to the global model. This helps reduce instability when client datasets vary a lot.
-
FedAdam Brings the popular Adam optimizer into federated learning. Instead of just averaging updates, it adapts learning rates and uses momentum to speed up and stabilize training—especially useful when data is inconsistent across clients.
-
FedAdaGrad Adapts the AdaGrad optimizer for federated learning. Each client adjusts its learning rate based on past gradients, so common patterns converge faster while rare ones don’t get overemphasized. Great for clients with very different data characteristics.
-
FedAvgM (FedAvg with Momentum) Adds a momentum term to FedAvg. Rather than averaging updates naively, it considers past updates too, which smooths training and reduces oscillations. This makes it more stable in challenging federated setups.
Federated Instructed Tuning
To make the project feasible within limited time and compute resources, I used smaller T5 models instead of larger LLMs. While compact, T5 still captures many of the behaviors of bigger models, making it a practical stand-in (proxy model) for testing federated learning in financial instruction tasks. This approach demonstrates that meaningful research can still be done responsibly, without requiring massive infrastructure.
Training Setup
To ensure a fair comparison between the baseline (centralized training) and federated learning, both were trained for a total of 9 epochs:
Baseline (centralized): 9 epochs straight
Federated models: 3 epochs × 3 rounds = 9 epochs total
Key training settings:
Batch size: 64 (with auto-adjust to fit hardware)
Optimizer: Adafactor + cosine learning rate scheduler
Learning rate: 2e-5
Weight decay: 0.01 (to reduce overfitting)
Max sequence length: 512 tokens
Precision: bfloat16 (bf16) for efficiency
Packing: Enabled (to improve efficiency with variable-length inputs)
Evaluation & logging: Every 50 steps (tracked with Weights & Biases)
Hardware: Google Colab A100 GPU, optimized with 10 dataloader workers
Checkpoints: Saved in safetensors format for compatibility and security
This setup was tuned to strike a balance between efficiency, performance, and generalization on the financial instruction dataset.
Evaluation Metrics
Since the models generate text, I evaluated them using ROUGE (ROUGE-1, ROUGE-2, ROUGE-L, ROUGE-SUM) and BLEU. These metrics measure how closely the model’s output matches the reference answers, focusing on overlap of words, phrases, and sequences.
Results
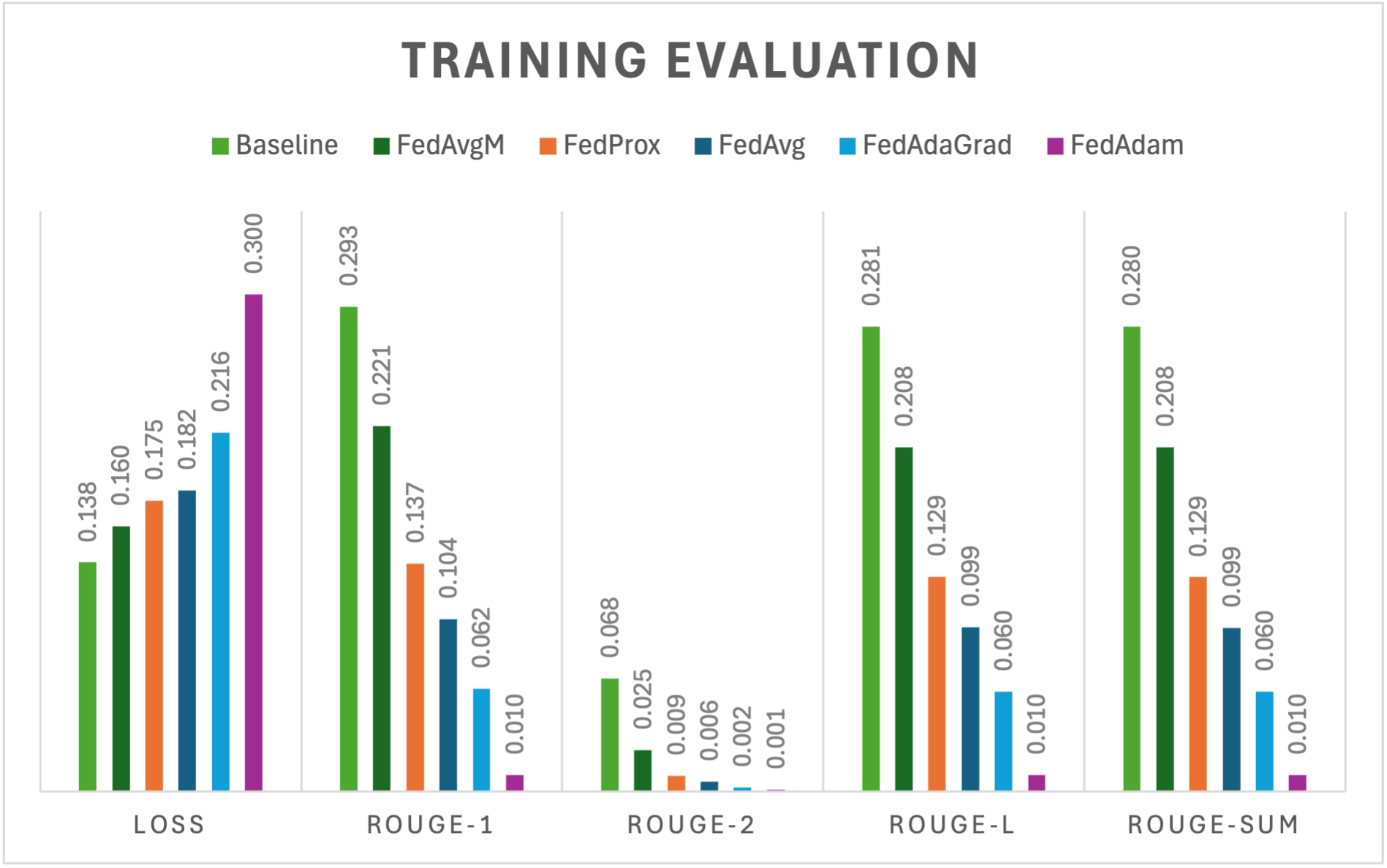
Finetuning Training Evaluation
The experiments revealed a clear performance hierarchy:
- Baseline (centralized training): As expected, this model performed best across all metrics. It served as the benchmark for comparison.
- FedAvgM (with momentum): Consistently the top-performing federated strategy. It achieved the lowest loss (0.160) and the highest ROUGE scores, outperforming FedProx (0.175 loss), FedAvg (0.182), and FedAdaGrad (0.216).
- FedAdam: Surprisingly, this strategy lagged far behind the others. Its performance dropped significantly across both loss and ROUGE metrics.
In short: while federated models still trailed the centralized baseline, FedAvgM showed strong promise as a practical strategy for stabilizing training and improving text generation quality in federated setups.
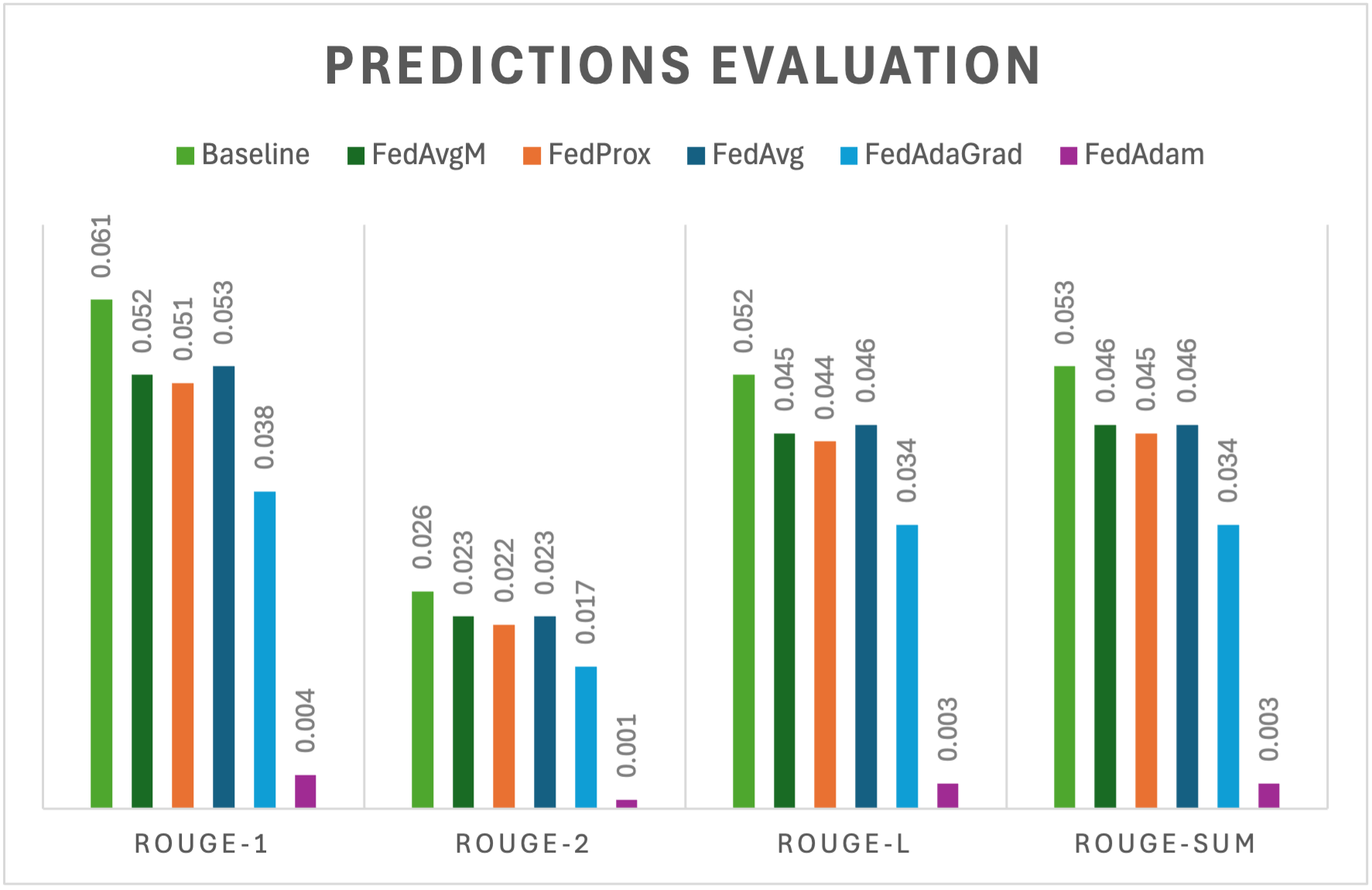
Predictions Evaluation
When evaluating predictions with ROUGE metrics, the results aligned closely with the training phase but revealed some interesting nuances:
- Baseline (centralized training): Maintained its lead, confirming its role as the strongest benchmark.
- FedAvgM, FedProx, and FedAvg: Performed very similarly during prediction, with ROUGE-SUM scores clustered at 0.046 (FedAvgM), 0.045 (FedProx), and 0.046 (FedAvg). This suggests that, in practice, their performance differences are marginal.
- FedAdaGrad: While competitive during training, its performance dipped slightly in prediction evaluation, falling behind the leading strategies.
- FedAdam: Consistently underperformed, with a ROUGE-SUM score of just 0.003, far below all other strategies.
Takeaways
The experiments highlighted several important findings about federated optimization strategies for fine-tuning language models on financial data:
-
FedAvgM consistently leads Across all metrics, FedAvgM outperformed other federated strategies. Its use of momentum helped speed up convergence and reduce instability during training, making it especially effective in decentralized settings. This mirrors findings from other research showing that momentum improves stability in distributed optimization.
-
Domain-specific challenges Because the dataset consisted of finance-related chats and responses, models had to capture precise terminology and context. Federated learning complicates this further, since each client may have slightly different distributions of financial text. FedAvgM’s stability appears to help the model generalize better across these variations while preserving terminological accuracy.
-
Impact of model size The project used T5-small, which has far fewer parameters than large models like GPT. While this made training feasible, smaller models are generally more sensitive to data heterogeneity in federated setups. This may explain why some strategies struggled: they simply don’t have the capacity to absorb highly diverse updates. The weak performance of FedAdam further supports this idea, as Adam-based optimizers are known to struggle in federated environments with non-IID client data.
-
ROUGE scores matter in finance Since financial conversations require both accuracy and fluency, ROUGE scores were especially relevant. Higher ROUGE indicates the model captured the right terminology while staying coherent. FedAvgM’s strong ROUGE results suggest it not only reduced loss but also generated more consistent, domain-appropriate responses.
-
FedAdam underperformed One unexpected finding was how poorly FedAdam performed compared to other strategies. While Adam is a go-to optimizer in centralized deep learning, it doesn’t translate well to federated learning. Its adaptive moment updates seem too unstable when client data is non-IID, reinforcing the need to carefully re-evaluate optimizers before applying them in decentralized contexts.